传闻中 OpenAI 的 Q* 已经引得 AI 大佬轮番下场。AI2 研究科学家 Nathan Lambert 和英伟达高级科学家 Jim Fan 都激动地写下长文,猜测 Q * 和思维树、过程奖励模型、AlphaGo 有关。 人类离 AGI,已是临门一脚了? OpenAI 的神秘 Q * 项目,已经引爆整个 AI 社区! 疑似接近 AGI,因为巨大计算资源能解决某些数学问题,让 Sam Altman 出局董事会的导火索,有毁灭人类风险…… 这些元素单拎出哪一个来,都足够炸裂。 无怪乎 Q * 项目曝出三天后,热度还在持续上升,已经引起了全网 AI 大佬的探讨。 AI2 研究科学家 Nathan 激动地写出一篇长文,猜测 Q 假说应该是关于思想树 + 过程奖励模型。而且,Q * 假说很可能和世界模型有关!
几小时后,英伟达高级科学家 Jim Fan 也发出长文分析,跟 Nathan 的看法不谋而合,略有不同的是,Jim Fan 的着重点是和 AlphaGo 的类比。 对于 Q*,Jim Fan 发出了如此赞叹:在我投身人工智能领域的十年中,我从来见过有这么多人对一个算法有如此多的想象!即使它只有一个名字,没有任何论文、数据或产品。 相比之下,图灵三巨头 LeCun 则认为,提升大 LLM 可靠性的一个主要挑战是,利用规划策略取代自回归 token 预测。 几乎所有顶级实验室都在这方面进行研究,而 Q * 则很可能是 OpenAI 在规划领域的尝试。 以及,请忽略那些关于 Q * 的毫无根据的讨论。
对此,Jim Fan 深表赞同:担心「通过 Q * 实现 AGI」是毫无根据的。 「AlphaGo 式搜索和 LLM 的结合,是解决数学和编码等特定领域的有效方法,同时还能提供基准真相的信号。但在正式探讨 AGI 之前,我们首先需要开发新的方法,将世界模型和具身智能体的能力整合进去。」
Q-Learning 忽然大火 两天前,外媒曝出,OpenAI 的神秘 Q * 项目,已现 AGI 雏形。
突然间,一项来自 1992 年的技术 ——Q-learning,就成为了大家竞相追逐的焦点。 简单来说,Q-learning 是一种无模型的强化学习算法,旨在学习特定状态下某个动作的价值。其最终目标是找到最佳策略,即在每个状态下采取最佳动作,以最大化随时间累积的奖励。 在人工智能领域,尤其是在强化学习中,Q-learning 代表了一种重要的方法论。 很快,这个话题引发了各路网友的激烈讨论: 斯坦福博士 Silas Alberti 猜测,它很可能是基于 AlphaGo 式蒙特卡罗树搜索 token 轨迹。下一个合乎逻辑的步骤是以更有原则的方式搜索 token 树。这在编码和数学等环境中尤为合理。
随后,更多人猜测,Q * 指的就是 A * 算法和 Q 学习的结合! 甚至有人发现,Q-Learning 竟然和 ChatGPT 成功秘诀之一的 RLHF,有着千丝万缕的联系! 随着几位 AI 大佬的下场,大家的观点,愈发不谋而合了。 AI 大佬千字长文分析 对于引得众人好奇无比的 Q * 假说,AI2 研究科学家 Nathan Lambert 写了如下一篇长文分析 ——《Q* 假说:思维树推理、过程奖励模型和增强合成数据》。
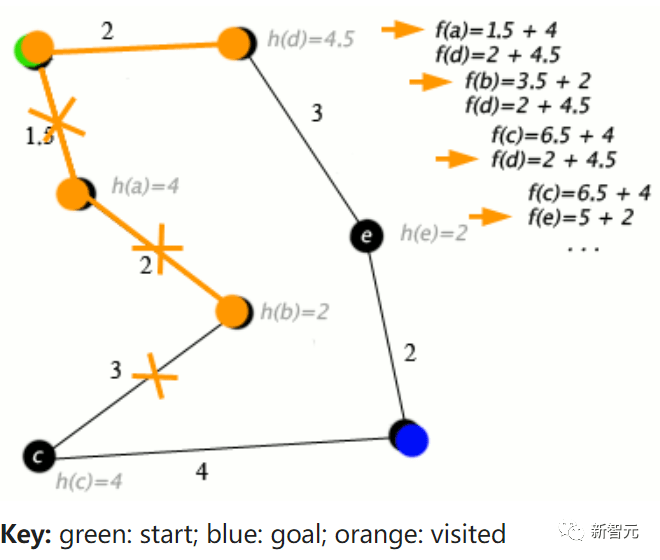
文章地址: https://www.interconnects.ai/p / q-star Lambert 猜测,如果 Q*(Q-Star)是真的,那么它显然是 RL 文献中的两个核心主题的合成:Q 值和 A*(一种经典的图搜索算法)。
A * 算法的一个例子 很多天来,坊间关于 Q 冒出了很多猜测,有一种观点认为,Q 指的是最优策略的值函数,不过在 Lambert 看来这不太可能,因为 OpenAI 已经几乎泄露了所有内容。 Lambert 将自己的猜测称为「锡帽理论」,即 Q 学习和 A * 搜索的模糊合并。 所以,正在搜索的是什么?Lambert 相信,OpenAI 应该是在通过思想树推理来搜索语言 / 推理步骤,来做一些强大的事情。 如果仅是如此,为何会引起如此大的震动和恐慌呢? 他觉得 Q * 被夸大的原因是,它将大语言模型的训练和使用与 Deep RL 的核心组件联系起来,而这些组件,成功实现了 AlphaGo 的功能 —— 自我博弈和前瞻性规划。 其中,自我博弈(Self-play)理论是指,智能体可以和跟自己版本略有不同的另一个智能体对战,来改善游戏玩法,因为它遇到的情况会越来越有挑战性。 在 LLM 领域,自我博弈理论看起来就像是 AI 反馈。
前瞻性规划(Look-ahead planning),是指使用世界模型来推理未来,并产生更好的行动或输出。 这种理论基于模型预测控制(MPC)和蒙特卡洛树搜索(MCTS),前者通常用于连续状态,后者适用于离散动作和状态。
https://www.researchgate.net/publication/320003615_MCTSUCT_in_solving_real-life_problems Lambert 之所以做出这种推测,是基于 OpenAI 和其他公司最近发布的工作。这些工作,回答了这样两个问题 ——
如果想明白了这两个问题,我们就该清楚,应该如何使用用于 RLHF 的 RL 方法 —— 我们用 RL 优化器来微调语言模型,并且通过模块化奖励,获得更高质量的生成(而不是像今天那样,完整的序列)。
使用 LLM 进行模块化推理:思维树(ToT)提示 现在,让模型「深呼吸」和「一步步思考」之类的方法,正在扩展到利用并行计算和启发式进行推理的高级方法上。 思维树是一种提示语言模型创建推理路径树的方法,这些路径可能会、也可能不会收敛到正确答案。
实现思维树的关键创新,就是推理步骤的分块,以及提示模型创建新的推理步骤。 思维树或许是第一个提高推理性能的「递归」提示技术,听起来非常接近人工智能安全所关注的递归自我改进模型。
https://arxiv.org/abs/2305.10601 使用推理树,就可以应用不同的方法来对每个顶点或节点进行评分,或者对最终路径进行采样。 它可以基于最一致答案的最小长度,或者需要外部反馈的复杂事物,而这恰恰就把我们带到了 RLHF 的方向。
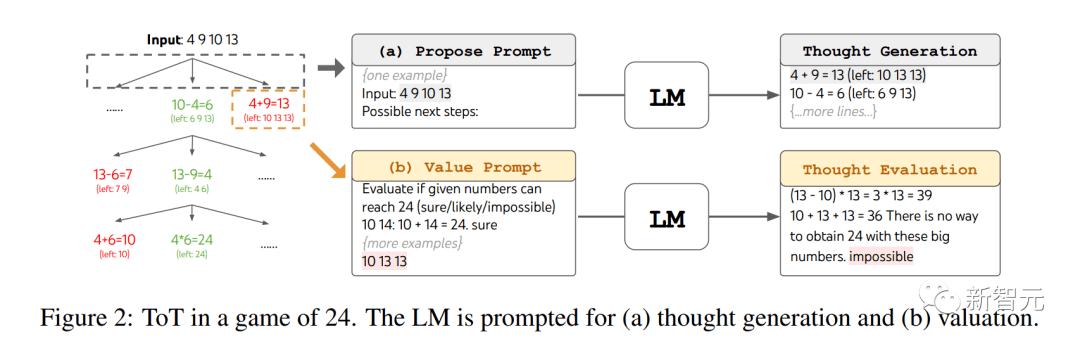
用思维树玩 24 点游戏 生成中的细粒度奖励标签:过程奖励模型(PRM) 迄今为止,大多数 RLHF,都是通过给模型的整个响应打分而完成的。 但对于具有 RL 背景的人,这种方法很令人失望,因为它限制了 RL 方法对文本的每个子组件的值建立联系的能力。 有人指出,在未来,这种多步骤优化将在多个对话回合的层面上进行,但由于需要有人类或一些提示源参与循环,整个过程仍然很牵强。 这可以很容易地扩展到自我博弈风格的对话上,但很难给出 LLM 一个目标,让它转化为持续改进的自我博弈动态。 毕竟,我们想用 LLM 做的大多数事情还是重复性任务,并不是像围棋那样,需要达到近乎无限的性能上限。
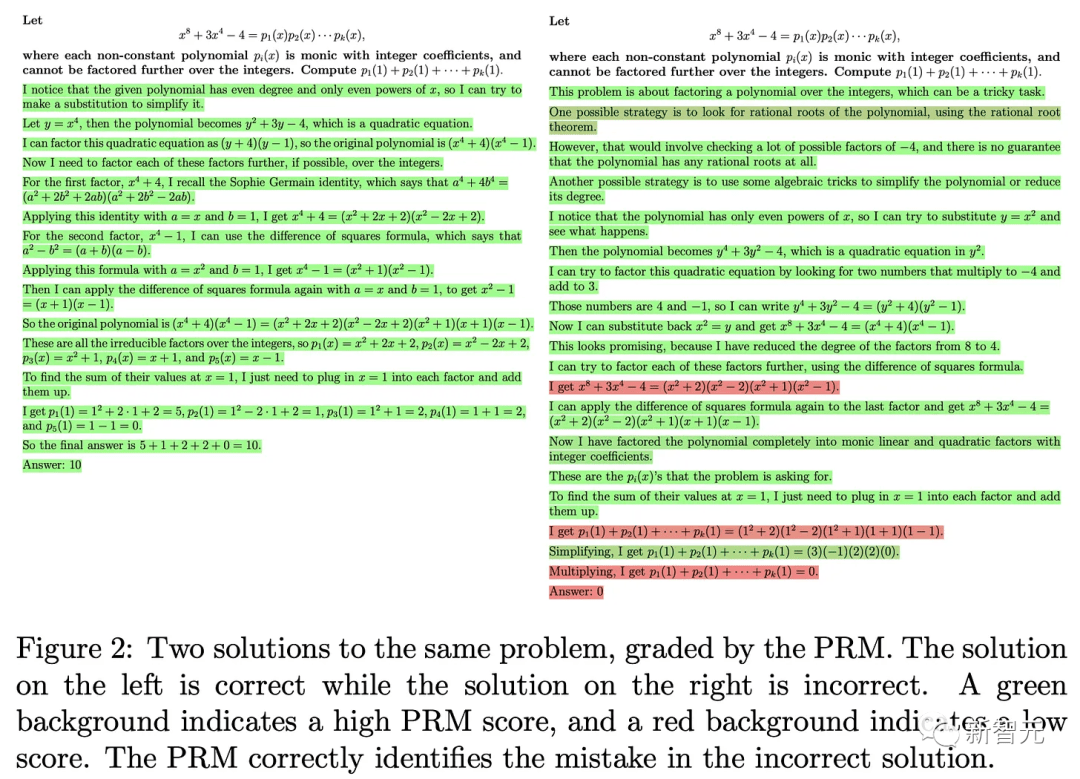
不过,有一种 LLM 用例,可以自然地抽象为包含的文本块,那就是分步推理。而最好的例子,就是解决数学问题。 过去 6 个月内,过程奖励模型(PRM)一直是 RLHF 人员热烈探讨的话题。 关于 PRM 的论文很多,但很少有论文会提到,如何将它们与 RL 结合使用。 PRM 的核心思想,就是为每个推理步骤分配一个分数,而不是一个完整的信息。 OpenAI 的论文「Let's Verify Step by Step」中,就有这样一个例子 ——
在这个过程中,他们使用的反馈界面长这个样子,非常有启发性。
这样,就可以通过对最大平均奖励或其他指标进行采样,而不是仅仅依靠一个分数,对推理问题的生成进行更精细的调整。 使用「N 最优采样」(Best-of-N sampling),即生成一系列次数,并使用奖励模型得分最高的一次,PRM 在推理任务中的表现,要优于标准 RM。 (注意,它正是 Llama 2 中「拒绝采样」Rejection Sampling 的表兄弟。) 而且迄今为止,大多数 PRM 仅展示了自己在推理时的巨大作用。但如果把它用于训练进行优化,就会发挥真正的威力。 而为了创建最丰富的优化设置,就需要能够生成用于评分和学习的多种推理路径。 这,就是思维树的用武之地。
人气极高的数学模型 Wizard-LM-Math,就是使用 PRM 进行训练的: https://arxiv.org/abs / 2308.09583 所以,Q * 可能是什么? Nathan Lambert 猜测,Q * 似乎正在使用 PRM,对 ToT 推理数据进行评分,然后再使用 Offline RL 进行优化。 这与现有的 RLHF 工具没有太大区别,它们用的是 DPO 或 ILQL 等离线算法,这些算法在训练期间不需要从 LLM 生成。 RL 算法看到的「轨迹」,就是推理步骤的序列,因此,我们得以用多步方式,而不是通过上下文,来执行 RLHF。 现有的传言显示,OpenAI 正在将离线 RL 用于 RLHF,这似乎不是一个很重大的飞跃。 它的复杂性在于要收集正确的提示,让模型生成出色的推理,而最重要的,就是准确地给数以万计的响应评分。 而传闻中的庞大计算资源,就是使用 AI 而非人类,来给每一步打分。
的确,合成数据才是王道,使用树而非单一宽度路径(思维链),就可以为以后越来越多的选择,给出正确答案。 如果传言是真的,OpenAI 和其他模型的差距,无疑会很可怕。 毕竟,现在大多数科技公司,比如谷歌、Anthropic、Cohere 等,创建预训练数据集用的还是过程监督或类似 RLAIF 的方法,轻易就会耗费数千个 GPU 小时。 超大规模 AI 反馈的数据未来 根据外媒 The Information 的传言,Ilya Sutskever 的突破使 OpenAI 解决了数据荒难题,这样就有了足够的高质量数据来训练下一代新模型。 而这些数据,就是用计算机生成的数据,而非真实世界的数据。 另外,Ilya 多年研究的问题,就是如何让 GPT-4 等语言模型解决涉及推理的任务,如数学或科学问题。
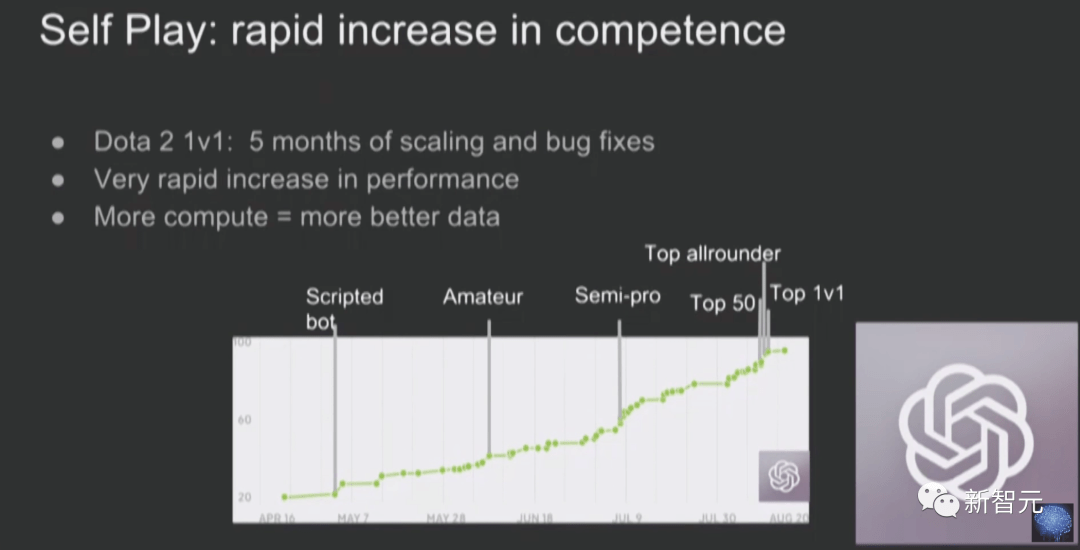
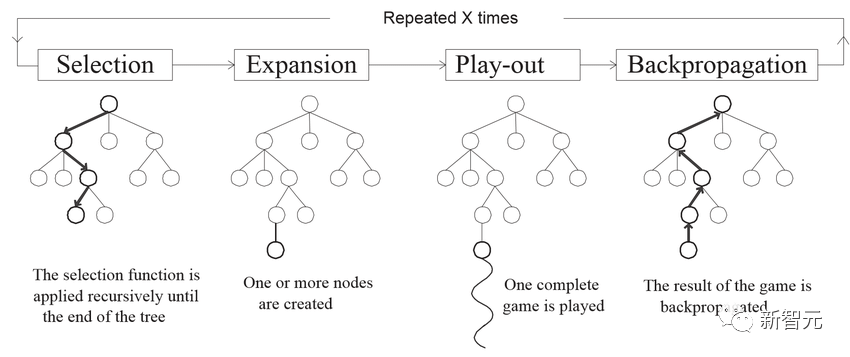
Nathan Lambert 表示,如果自己猜得没错,Q * 就是生成的合成推理数据。 通过类似剔除抽样(根据 RM 分数进行筛选)的方法,可以选出最优秀的样本。而通过离线 RL,生成的推理可以在模型中得到改进。 对于那些拥有优质大模型和大量算力资源的机构来说,这是一个良性循环。 结合 GPT-4 给大家的印象,数学、代码、推理,都应该是最从 Q * 技术受益的主题。 什么是最有价值的推理 token? 许多 AI 研究者心中永恒的问题是:究竟哪些应用值得在推理计算上花费更多成本? 毕竟,对于大多数任务(如阅读文章、总结邮件)来说,Q * 带来的提升可能不值一提。 但对于生成代码而言,使用最佳模型,显然是值得的。 Lambert 表示,自己脑子中有一种根深蒂固的直觉,来自于和周围人餐桌上的讨论 —— 使用 RLHF 对扩展推理进行训练,可以提高下游性能,而无需让模型一步一步思考。 如果 Q * 中实现了这一点,OpenAI 的模型,无疑会显示出重大的飞跃。 Jim Fan:Q * 可能的四大核心要素 Nathan 在我之前几个小时发布了一篇博客,并讨论了非常相似的想法:思想树 + 过程奖励模型。他的博客列出了更多的参考文献,而我更倾向于与 AlphaGo 的类比。 Jim Fan 表示,要理解搜索和学习结合的强大威力,我们需要先回到 2016 年,这个人工智能历史上的辉煌时刻。 在重新审视 AlphaGo 时,可以看到它包含了四个关键要素: 1. 策略神经网络(Policy NN,学习部分):评估每种走法获胜的可能性,并挑选好的走法。 2. 价值神经网络(Value NN,学习部分):用于评估棋局,从任意合理的布局中预测胜负。 3. 蒙特卡罗树搜索(MCTS,搜索部分):利用策略神经网络模拟从当前位置出发的多种可能的走法,然后汇总这些模拟的结果来决定最有希望的走法。这是一个「慢思考」环节,与大语言模型(LLM)中的快速 token 采样形成鲜明对比。 4. 推动整个系统的真实信号:在围棋中,这个信号就像「谁获胜」这种二元标签一样简单,由一套固定的游戏规则所决定。你可以把它想象成一种能量源,持续地推动着学习的进程。 那么,这些组件是如何相互作用的呢? AlphaGo 通过自我博弈(即与自己之前的版本对弈)来学习。 随着自我博弈的持续,策略神经网络和价值神经网络都在不断迭代中得到改善:随着策略在选择走法上变得更精准,价值神经网络也能获得更高质量的数据进行学习,进而为策略提供更有效的反馈。更强大的策略也有助于 MCTS 探索出更佳的策略。 这些最终构成了一个巧妙的「永动机」。通过这种方式,AlphaGo 能自我提升,最终在 2016 年以 4-1 的成绩击败了人类世界冠军李世石。仅仅通过模仿人类的数据,人工智能是无法达到超越人类的水平的。
对于 Q * 来说,又会包含哪四个核心组件呢? 1. 策略神经网络(Policy NN):这将是 OpenAI 内部最强大的 GPT,负责实现解决数学问题的思维过程。 2. 价值神经网络(Value NN):这是另一个 GPT,用来评估每一个中间推理步骤的正确性。 OpenAI 在 2023 年 5 月发布了一篇名为「Let's Verify Step by Step」的论文,作者包括 Ilya Sutskever、John Schulman 和 Jan Leike 等知名大佬。虽然它不像 DALL-E 或 Whisper 那样知名,但却为我们提供了不少线索。 在论文中,作者提出了「过程监督奖励模型」(Process-supervised Reward Models,PRM),它为思维链中的每一步提供反馈。相对的是「结果监督奖励模型」(Outcome-supervised Reward Models,ORM),它只对最终的整体输出进行评估。 ORM 是 RLHF 的原始奖励模型,但它的粒度太粗,不适合对长响应中的各个部分进行适当的评估。换句话说,ORM 在功劳分配方面表现不佳。在强化学习文献中,我们将 ORM 称为「稀疏奖励」(仅在最后给予一次),而 PRM 则是「密集奖励」,能够更平滑地引导 LLM 朝我们期望的行为发展。 3. 搜索:不同于 AlphaGo 的离散状态和动作,LLM 运行在一个复杂得多的空间中(所有合理字符串)。因此,我们需要开发新的搜索方法。 在思维链(CoT)的基础上,研究界已经开发出了一些非线性变体: - 思维树(Tree of Thought):就是将思维链和树搜索结合在一起 - 思维图(Graph of Thought):将思维链和图结合,就可以得到一个更为复杂的搜索运算符 4. 真实信号:(几种可能) (a)每个数学问题都有一个已知答案,OpenAI 可能已经从现有的数学考试或竞赛中收集了大量的数据。 (b)ORM 本身可以作为一种真实信号,但这样可能会被利用,从而「失去维持学习所需的能量」。 (c)形式化验证系统,如 Lean 定理证明器,可以把数学问题转化为编程问题,并提供编译器反馈。 就像 AlphaGo 那样,策略 LLM 和价值 LLM 可以通过迭代相互促进进步,并在可能的情况下从人类专家的标注中学习。更优秀的策略 LLM 将帮助思维树搜索发现更好的策略,这反过来又能为下一轮迭代收集更优质的数据。 Demis Hassabis 之前提到过,DeepMind 的 Gemini 将采用「AlphaGo 式算法」来增强推理能力。即使 Q * 不是我们所想象的那样,谷歌也一定会用自己的算法迎头赶上。 Jim Fan 表示,以上只是关于推理的部分。目前并没有迹象表明 Q * 在写诗、讲笑话或角色扮演方面会更具创造性。本质上,提高创造力是人的事情,因此自然数据仍将胜过合成数据。 是时候解决最后一章了 而深度学习专家 Sebastian Raschka 对此表示 —— 如果你出于任何原因,不得不在这个周末学习 Q-learning,并且碰巧在你的书架上有一本「Machine Learning with PyTorch and Scikit-Learn」,那么,现在是时候解决最后一章了。
|
|
标题 >> |
世界模型?OpenAI 神秘 Q * 引爆整个 AI 社区,全网大佬发文热议 |